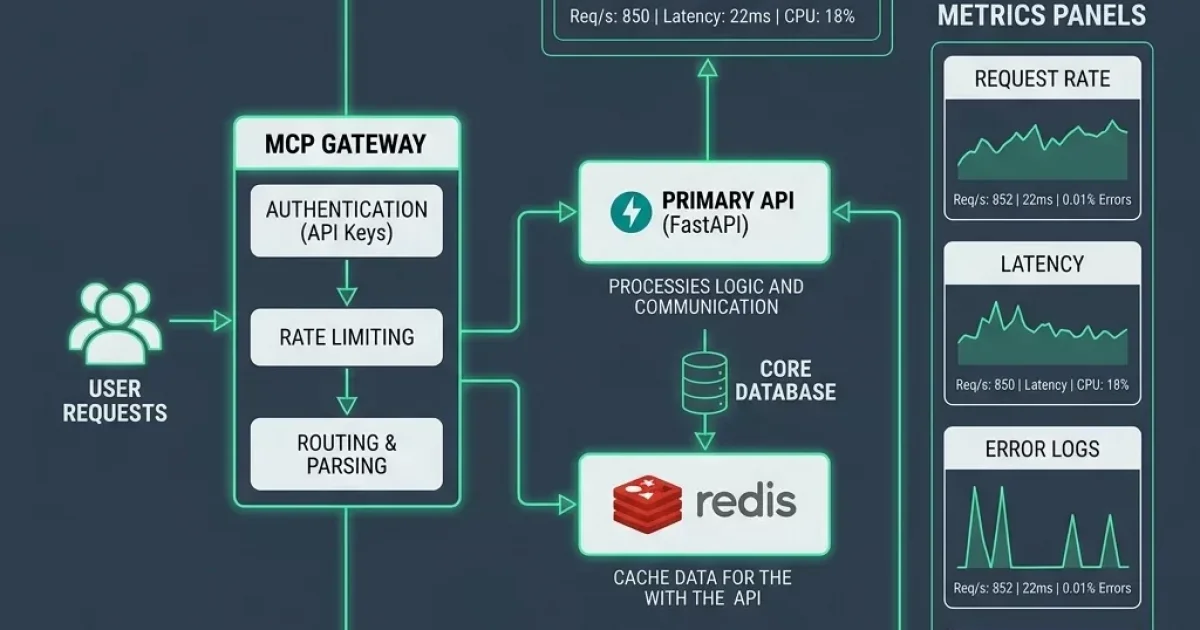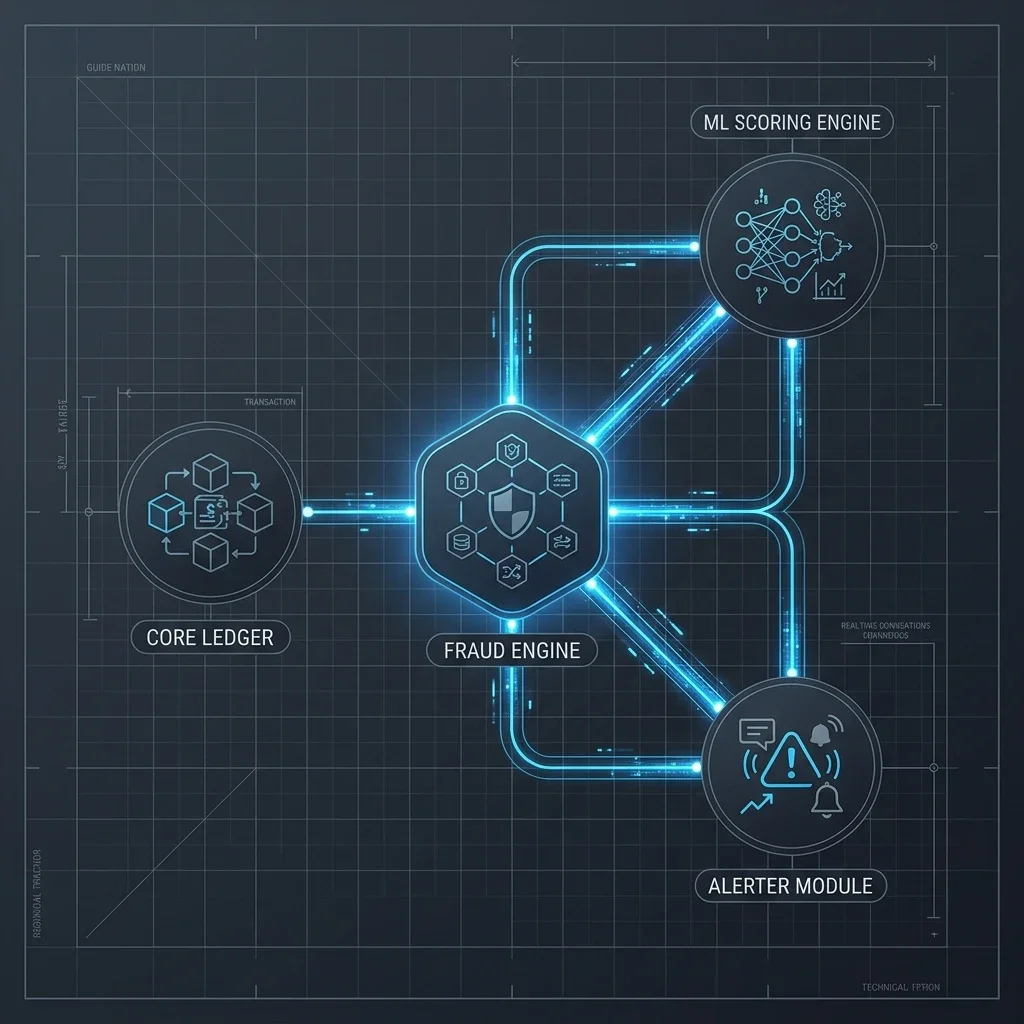
For commercial financial institutions, security compliance is a critical baseline that cannot be compromised. However, when compliance triggers a staggering vo…
For commercial financial institutions, security compliance is a critical baseline that cannot be compromised. However, when compliance triggers a staggering volume of false alarms, it becomes an operational bottleneck that threatens customer satisfaction and drains manual labor resources. For a regional Tier-2 bank managing over 2.1 million active deposit accounts and processing millions of daily transactions, their legacy fraud screening system had become a major point of friction.
Static, rule-based screening triggered thousands of alert flags daily. Over 95% of these flags were completely false positives, requiring a massive team of 40 compliance officers to manually review, verify, and unlock accounts. This overhead led to severe review backlogs, delayed transaction clearance, and customer frustration, while actual sophisticated fraud occasionally slipped through undetected.