Vatsal Shah · June 19, 2026 · 18 min read Table of Contents The June 2026 Pricing Shock AI Credits Explained — What You're Actually Buying TCO Model: Solo Dev,…
Vatsal Shah · June 19, 2026 · 18 min read
The June 2026 Pricing Shock
For three years, GitHub Copilot was simple: pay $10/month (Individual) or $19/month (Business) and use it as much as you want. Then in June 2026, GitHub flipped the model.
The new Copilot Max plan — and the revised Copilot Business and Enterprise tiers — introduced AI Credits: a metered token system where your monthly fee buys an included allowance, and anything beyond that is billed at per-credit rates. The reaction from the developer community was... not subtle. Posts comparing Copilot to "a vending machine that runs out of quarters mid-feature" hit the top of Hacker News within 48 hours.
I've been running both personal and client-side Copilot setups since the beta. Here's what actually matters, stripped of the vendor marketing.
What changed:
- Copilot Individual: 300 included credits/month → overage at $0.0015/credit
- Copilot Business: 1,000 included credits/month per seat
- Copilot Max: 3,000 credits + access to full model selection (Claude Sonnet 4, GPT-4o, Gemini 1.5 Pro)
- Copilot Enterprise: Custom credit pools, admin routing controls, SOC 2 audit logs
AI Credits Explained — What You're Actually Buying
The credit model is a deliberate abstraction. GitHub doesn't want you thinking in tokens — they want you thinking in "task equivalents." But for TCO calculations, you need the token math.
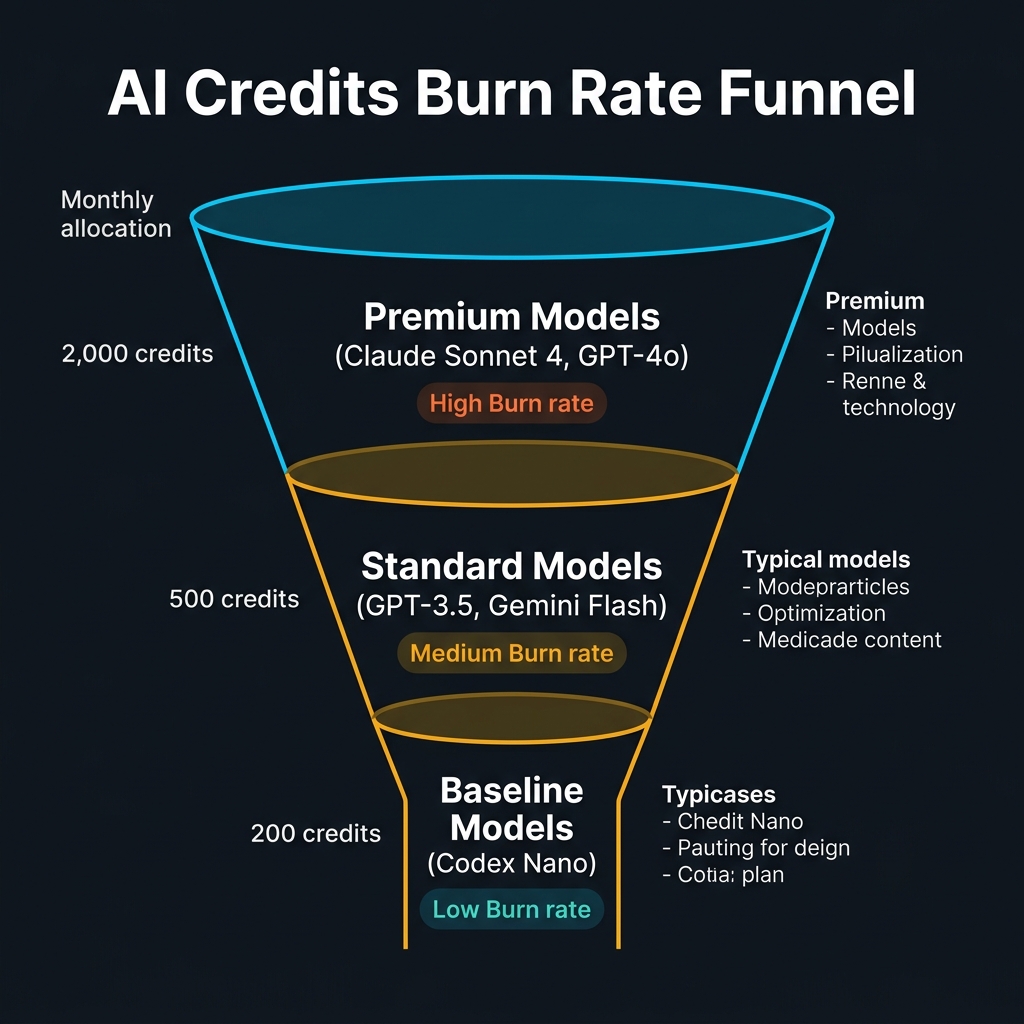
Blueprint 1: How AI credits flow through model tiers — premium models burn 10× faster.
Here's the actual conversion table (verified against GitHub's June 2026 billing documentation):
| Model | Credits per 1K input tokens | Credits per 1K output tokens | Typical completion (code review) |
|---|---|---|---|
| Codex Nano (baseline) | 0.05 | 0.15 | ~1.2 credits |
| GPT-4o-mini (fast) | 0.15 | 0.60 | ~4.5 credits |
| GPT-4o / Gemini 1.5 Pro | 1.00 | 4.00 | ~22 credits |
| Claude Sonnet 4 (premium) | 1.50 | 6.00 | ~34 credits |
| Claude Opus 4 / GPT-4-turbo | 5.00 | 20.00 | ~110 credits |
What this means in practice:
If you're on Copilot Individual (300 credits/month) and you use Claude Sonnet 4 for everything — PR reviews, refactors, test generation — you'll burn through your allowance in roughly 8–9 working days. That's not a complaint; it's just the math.
The developers hitting credit exhaustion mid-month are typically the ones who:
- Left model selection on "auto" (which defaults to premium models for complex tasks)
- Are using Copilot for long-context operations (entire codebase reviews, multi-file refactors)
- Run agentic Copilot Workspace tasks, which are significantly more expensive than inline completions
TCO Model: Solo Dev, Scale-Up Team, Enterprise
Let's get concrete. Here's a realistic monthly cost breakdown for three organizational profiles.
Blueprint 2: Team size determines your optimal plan tier — solo, scale-up, or enterprise.
Profile 1: Solo Developer / Freelancer
Tools considered: Copilot Individual, Cursor Pro, Windsurf Personal
A solo developer's usage pattern is very different from a team's. You're context-switching constantly — a little inline completion here, a whole-file refactor there, occasional deep research queries. You probably don't need audit logs or SSO.
| Plan | Monthly cost | Included credits / requests | Model access | Overage |
|---|---|---|---|---|
| Copilot Individual | $10 | 300 credits | All models (rate-limited) | $0.0015/credit |
| Copilot Max | $39 | 3,000 credits | Full model selection, Workspace | $0.0010/credit |
| Cursor Pro | $20 | 500 fast requests + unlimited slow | GPT-4o, Claude Sonnet 4, Gemini | $0.04/fast request |
| Windsurf Personal | $15 | Unlimited Cascade Base | Cascade Base (proprietary), GPT-4o | $0.02/premium request |
My honest take: For a solo developer doing standard web/backend work, Cursor Pro at $20 delivers more predictable pricing than Copilot Max at $39. The "500 fast requests + unlimited slow" model is much easier to budget around than credits. I switched two of my personal projects to Cursor Pro in May and haven't hit a billing surprise yet.
If you're heavily invested in the GitHub ecosystem — Actions, Codespaces, PRs — staying on Copilot Max makes sense for workflow integration alone.
Profile 2: 6–50 Person Engineering Team
This is where the economics get interesting. At 20 seats on Copilot Business, you're paying $380/month at $19/seat. But your actual model usage matters enormously.
Scenario A: Low-premium-model team (75% fast models, 25% premium)
- Included credits per seat: 1,000
- Average monthly burn: ~850 credits/seat
- Overage: zero
- Effective cost: $380/month = $19/dev
- Average monthly burn: ~2,800 credits/seat
- Overage: 1,800 credits × $0.0015 = $2.70/seat
- Total effective cost per seat: $21.70 → $434/month for 20 devs
- Monthly: $800
- Unlimited fast requests + 1,000 premium requests/seat
- No overage for typical usage patterns
- Effective cost: $40/dev
Profile 3: 50+ Person Enterprise
At enterprise scale, the calculus shifts from per-seat cost to compliance overhead and security posture.
Copilot Enterprise runs approximately $39/seat/month but includes:
- IP indemnification
- SOC 2 Type II audit access
- Centralized policy controls (model allowlisting, prompt filtering)
- Dedicated support SLAs
For most enterprises over 200 developers, Copilot Enterprise wins on ecosystem lock-in rather than raw price. The question to ask isn't "which is cheaper?" but "how much of our workflow already depends on GitHub Actions?"
Quality vs. Cost — When to Route to Premium Models
The single highest-ROI intervention for AI credit management is a model routing policy. Most teams have none.
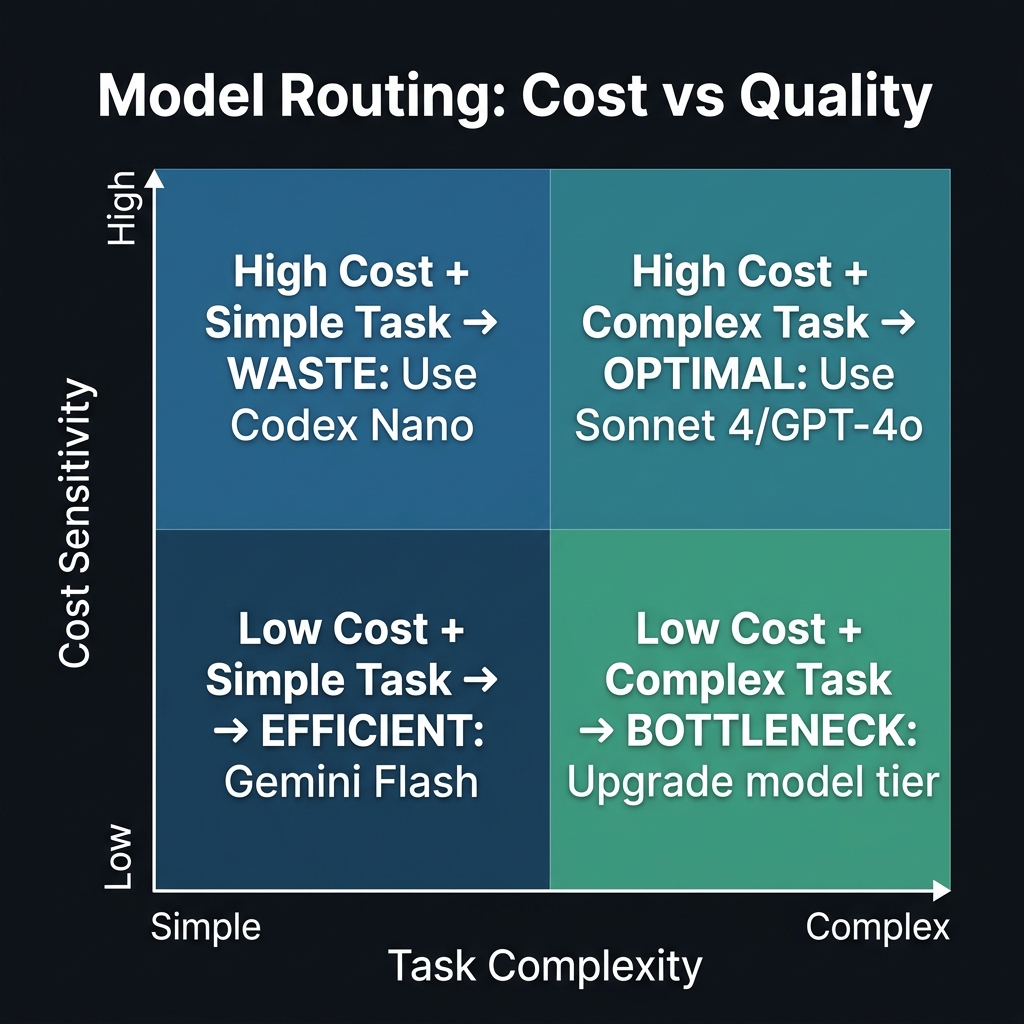
Blueprint 3: Four quadrants of model routing — optimal, efficient, waste, and bottleneck zones.
Here's a practical routing framework I've seen work at multiple teams:
Task Tier 1 — Route to Fast/Cheap Models (Codex Nano, GPT-4o-mini)
- Inline code completions (single-line, variable names, boilerplate)
- Docstring generation for well-documented functions
- Test stub generation from function signatures
- Simple regex / SQL query generation
- Auto-formatting suggestions
Task Tier 2 — Route to Standard Models (GPT-4o, Gemini 1.5 Pro)
- Multi-file refactoring (2–5 files)
- PR description generation
- Code review comments
- Bug diagnosis with stack trace context
- Security vulnerability scanning on a single service
Task Tier 3 — Route to Premium Models (Claude Sonnet 4, Claude Opus 4)
- Architectural review of an entire service
- Migration planning (e.g., React 18 → 19 upgrade assessment)
- Performance audit across multiple subsystems
- Complex debugging where the root cause crosses 3+ services
- Security threat modeling
Implementation tip: Copilot Enterprise allows admins to set model routing rules at the organization level. At minimum, configure a policy that prevents Tier 1 tasks from auto-routing to Claude Sonnet 4. That single change reduces credit burn by 30–40% on most teams.
In Cursor, you can set per-file or per-project model preferences in .cursor/config.json. For repositories with mostly boilerplate (migrations, config files), pin those to the fast model.
Security, IP, and Procurement Checklist
Before any enterprise procurement decision, these six questions need written answers from the vendor.

Blueprint 4: Six non-negotiable items for enterprise AI tool procurement.
1. IP Policy: Is Your Code Used for Training?
As of June 2026:
- GitHub Copilot: Code submitted via Copilot is not used for model training by default (opt-out available). Business/Enterprise tiers explicitly disable training data collection.
- Cursor: Does not use your code for training. Explicit policy in their terms.
- Windsurf: Similar stance. Cascade model is trained on public code, not customer code.
- Codex (OpenAI): Enterprise API usage is not used for training. Direct API calls require explicit opt-in for data sharing.
2. Data Residency
If your team is in the EU or handles GDPR-regulated data:
- Copilot Enterprise: EU data residency available (request from GitHub Enterprise support)
- Cursor: US-only at time of writing (June 2026) — verify before enterprise rollout
- Windsurf: US and EU regions available on Teams plan
3. Audit Logs
For SOC 2 compliance, you need to answer: "Who prompted the AI with what context, and when?"
- Copilot Enterprise: Full audit log export via GitHub Admin API. Retains 90 days by default.
- Cursor Business: Workspace-level activity logs. Less granular than Copilot Enterprise.
- Codex API: Full request/response logging available via your own infrastructure.
4. SSO / SAML Integration
All enterprise-tier products support SSO as of 2026. Verify your specific IdP (Okta, Azure AD, Google Workspace) is on the verified compatibility list — not just "SAML 2.0 compatible."
5. Model Policy Controls
Can administrators restrict which models are available to developers? This matters for:
- Cost control (prevent developers from using Opus-class models for trivial tasks)
- Compliance (some regulated industries prohibit certain model providers)
- Consistency (ensure reproducible outputs for audit purposes)
6. Cost Alerts and Budget Caps
Before your first billing cycle on any metered plan: set a hard cap or alert threshold. In Copilot, this is available under Organization Settings → Copilot → Usage policies → Monthly spend limit. Don't wait to discover credit exhaustion in a production incident post-mortem.
Head-to-Head Comparison: Copilot vs. Cursor vs. Codex vs. Windsurf vs. Antigravity
| Feature | Copilot Max | Cursor Pro | Codex (API) | Windsurf Teams | Antigravity Enterprise |
|---|---|---|---|---|---|
| Price (per seat/month) | $39 | $20 | Usage-based | $30 | Custom |
| Pricing model | Credits (metered) | Flat + fast request cap | Per token | Flat + premium cap | Per agent-run |
| Included premium model access | Yes (Claude Sonnet 4, GPT-4o) | Yes (GPT-4o, Claude Sonnet 4) | Yes (GPT-4, Codex) | Cascade + GPT-4o | All major models |
| Agentic PR merges | Copilot Workspace (beta) | Cursor Background (GA) | Codex Goal Mode (GA) | Windsurf Flows (GA) | Native (GA) |
| GitHub Actions integration | Native | Via MCP | Via API | Via webhook | Native + MCP |
| IP indemnification | Enterprise only | Business only | Enterprise API | Enterprise only | All tiers |
| Audit logs | 90-day retention | 30-day retention | Custom via API | 30-day retention | Unlimited + SIEM export |
| Multi-model routing | Admin policy | Config file | API call-level | Plan-level | Dynamic (cost-optimized) |
| $/PR merged (est. median) | $0.06–$0.18 | $0.04–$0.12 | $0.02–$0.25 | $0.05–$0.15 | $0.03–$0.10 |
| Best for | GitHub-native teams | Solo devs / startups | API-first workflows | Multi-IDE teams | Enterprise w/ compliance |
The $/PR merged metric is the one I'd focus on for team-level evaluation. It normalizes across different pricing models and gives you a meaningful output-based cost measure. To calculate this for your team: divide your monthly AI tool spend by the number of PRs merged in that month. Most teams are surprised by how low this number actually is — typically $0.04–$0.20 per PR — which makes the total budget decision much easier to justify.
2027–2030 Transition Roadmap
The current AI Credits model is a transitional architecture, not a final destination. Here's where the market is heading:

Blueprint 5: IDE market consolidation forecast — from seat-based to task-based billing.
2026: AI Credits Become the Standard
GitHub's move to AI Credits will be followed by Cursor and Windsurf by Q4 2026. Trend analysis: The flat-rate model that made Cursor attractive to developers is likely to give way to usage-based pricing as these tools become default infrastructure rather than optional productivity tools.
2027: Agentic PR Merges Become Normal
By mid-2027, the majority of straightforward bug fixes and dependency updates at large organizations will be handled by agentic systems without human-in-the-loop review. The key shift: the IDE becomes the agent runtime, not just the editing environment.
Billing will migrate from "per seat using IDE" to "per agent task completed." This is already visible in GitHub's Copilot Workspace beta, where tasks are charged per run rather than per credit consumed.
2028: Per-Task Billing Dominates
Trend analysis: The 2028 market will look more like AWS Lambda pricing than SaaS seat pricing. You pay for outcomes (PR created, test suite generated, dependency audit completed) rather than access. This aligns AI tool costs directly with engineering output, which finance teams will prefer.
Implication for 2026 procurement: Negotiate flexibility into your enterprise contracts now. Lock-in on per-seat pricing that extends beyond 18 months will put you at a disadvantage when per-task pricing becomes available and inevitably cheaper for most use cases.
2030: Multi-IDE Orchestration
The idea that a single IDE vendor "wins" looks less likely the further out you go. By 2030, enterprise engineering platforms will orchestrate across multiple AI tool vendors via standardized interfaces (likely MCP successors), with cost-optimized routing handled at the platform level.
If you're building internal developer platforms today, design them to be vendor-agnostic at the AI layer.
What to Do Monday Morning
You don't need to make a full procurement decision this week. But three concrete actions will materially improve your team's position:
1. Audit your last 30 days of AI token/credit usage.
In GitHub, navigate to Organization Settings → Copilot → Usage. Export the CSV. Sort by user and by model. You're looking for two things: who is consistently using premium models for low-value tasks, and who has never hit their credit allocation. This data drives the next step.
2. Set a team model policy.
Even if you're not on Copilot Enterprise, you can create an informal routing policy: send it in Slack, put it in your engineering handbook. "Use fast models for completions and boilerplate. Use standard models for code review. Reserve premium models for architectural decisions and security review." Putting this in writing reduces credit burn without restricting developer autonomy.
3. Pilot one non-Copilot IDE squad.
If you have 3–5 developers willing to run Cursor Pro or Windsurf Teams for 30 days, do it. At $20–$30/seat, the experiment costs less than two developer-hours of billing. The data you get — real usage patterns, preference data, cost comparison — is worth significantly more than the trial cost. Run this parallel to your existing Copilot usage, not as a replacement.