

Table of Contents From Dev Experiments to Enterprise Catalog What Is an MCP Registry? (Featured Snippet) Why MCP Governance Matters in 2026 Auth Patterns — OAut…
From Dev Experiments to Enterprise Catalog
When developers first discovered Model Context Protocol (MCP), the instinct was to wire up a local server and get it running before lunch. Anthropic released the specification in late 2024 and, within months, Claude Desktop, Cursor, and every agentic SDK worth mentioning had native MCP support.
The problem is that "works on my laptop" MCP is nothing like enterprise MCP.
Here's what I see in practice. Teams start with one MCP server serving the file system. A few weeks later there's a second one for the database. Then someone wires up Slack, GitHub, and Jira — each with its own long-lived API key baked into a config file, each running as a separate process with zero coordination. By the time an AI governance conversation starts, the platform team is already counting eight rogue MCP servers across three product groups, none of them audited, none of them versioned.
If you've read my MCP 101 guide, you know the protocol basics. This article assumes you're past that. What we're covering here is the infrastructure layer that turns a cluster of dev experiments into a production-grade tool platform.
The shift isn't just technical. It's organizational. You need to think of your MCP estate the same way you'd think about an internal API marketplace — every tool server is a registered service, every connection has an identity, and every call lands in an audit log.
Let's build that.

What Is an MCP Registry?
An MCP registry is a centralized catalog and control plane for all MCP servers in an organization. It stores metadata about each registered tool server — its slug, version, schema, owner, allowed client groups, and deprecation status — and exposes a gateway endpoint that enforces authentication, rate limits, and schema contracts before proxying tool calls to the correct backend server.
Think of it as the intersection of a service registry (like Consul) and an API gateway (like Kong or AWS API Gateway), purpose-built for the JSON-RPC-over-SSE communication pattern that MCP uses.
A minimal production registry has four moving parts:
- Registry database — stores tool server metadata, capability manifests, and version history
- Gateway process — the single ingress point for all client → tool traffic
- Auth service — issues and validates short-lived tokens for each client–tool session
- Audit log — every tool call, every schema validation failure, every auth rejection
Why MCP Governance Matters in 2026
Three things happened this year that made MCP governance mandatory rather than optional.
First, the stateless MCP spec. The July 2026 final release of the MCP specification moves toward a fully stateless transport model — sessions become token-bound, not connection-bound. That's good for scalability, but it means every call now carries its own auth context. Bolt-on auth no longer works. You need auth baked into the gateway.
Second, enterprise AI adoption accelerated past the point where informal trust works. A Gartner estimate from Q1 2026 puts 47% of Fortune 1000 firms running at least one production agentic AI workload. Agents don't just read data — they write, schedule, and execute. A misconfigured tool connection is a blast radius, not just an inconvenience.
Third, shadow MCP servers are already a real attack surface. An engineer installs Claude Desktop, points it at an internal Postgres MCP server, and does a demo. They leave the MCP server running. Three months later, that server is accessible on port 3000 from anywhere on the corporate network. This is the MCP equivalent of shadow IT, and I've personally seen it in two separate enterprise engagements in 2026.
The good news: if you read the surviving shadow AI playbook, the governance muscle you built for LLM usage applies directly here. MCP is just a new surface area to monitor.
Auth Patterns — OAuth, mTLS, and Per-Tenant API Keys
The MCP specification is transport-agnostic about auth. That's intentional — the protocol stays lean, and you pick what fits your threat model. In enterprise deployments I've worked on, three patterns dominate.
OAuth 2.0 (for human-in-the-loop clients)
When a developer uses Claude Desktop or Cursor, they're a human authenticating interactively. OAuth 2.0 with PKCE is the right choice. The flow:
- Client initiates a tool call
- Gateway redirects to your identity provider (Okta, Azure AD, Auth0)
- User authenticates, receives short-lived access token (15-minute TTL)
- Token is presented with every MCP JSON-RPC call
- Gateway validates token signature and checks tool-level scope claims
mcp:tool:filesystem:read and enforce them at the gateway before routing.
mTLS (for machine-to-machine agents)
When an autonomous agent — a LangGraph workflow, a CrewAI crew, a custom Python script — needs to call tools, there's no human present to authenticate. This is where mutual TLS shines.
Each agent service gets a client certificate signed by your internal CA. The gateway validates both the server cert (normal TLS) and the client cert (mutual). The client cert contains the agent's identity in the Subject Alternative Name field. You map that identity to an allow-list of tools in your registry.
The practical upshot: revoke an agent's certificate and it immediately loses tool access — no token rotation, no config changes, no hunting down API keys.
# FastAPI MCP gateway with mTLS client validation (simplified)
import ssl
from fastapi import FastAPI, Request
app = FastAPI()
def get_client_identity(request: Request) -> str:
"""Extract agent identity from validated client certificate SAN."""
cert = request.scope.get("ssl_object").getpeercert()
# Extract subject CN or SAN
subject = dict(x[0] for x in cert.get("subject", []))
return subject.get("commonName", "unknown-agent")
@app.post("/mcp/{tool_slug}/rpc")
async def proxy_mcp(tool_slug: str, request: Request):
identity = get_client_identity(request)
if not registry.is_authorized(identity, tool_slug):
raise HTTPException(403, f"Agent {identity!r} not authorized for {tool_slug!r}")
return await forward_to_tool(tool_slug, await request.json())Per-Tenant API Keys (for SaaS multi-tenancy)
If you're building a product where each customer tenant can bring their own MCP tools, OAuth and mTLS are too heavyweight for onboarding. Per-tenant API keys — HMAC-signed, rotatable, scoped to a tenant namespace — are the right fit.
The gateway validates the key's HMAC signature, extracts the tenant ID from the key payload, and scopes all tool calls to that tenant's registered servers. Rate limits apply per tenant, not per user, which prevents one noisy tenant from degrading tool access for others.
// TypeScript gateway middleware: API key auth + tenant scoping
import { createHmac, timingSafeEqual } from 'crypto'
export function verifyApiKey(rawKey: string, secret: string): { tenantId: string } | null {
const [tenantId, nonce, signature] = rawKey.split('.')
if (!tenantId || !nonce || !signature) return null
const expected = createHmac('sha256', secret)
.update(`${tenantId}.${nonce}`)
.digest('hex')
const isValid = timingSafeEqual(
Buffer.from(signature, 'hex'),
Buffer.from(expected, 'hex')
)
return isValid ? { tenantId } : null
}
Gateway Layer — Rate Limits, Schema Validation, Versioning
The gateway is where your governance policy becomes code. Get these three right and most enterprise audit requirements follow naturally.
Rate Limiting (Per Identity, Not Per IP)
IP-based rate limiting doesn't work for enterprise MCP because most agent traffic comes from a small number of datacenter IP addresses. Rate limit by identity — the OAuth subject, the mTLS cert CN, or the tenant ID.
A reasonable starting point for a mid-scale deployment:
- Interactive developer: 100 tool calls/minute, burst to 200
- Autonomous agent service: 500 calls/minute, burst to 1,000
- Tenant namespace: 2,000 calls/minute total across all tools
Retry-After header. Never silently drop calls — agents retry dropped calls and your tool backends get hit harder, not less hard.
Schema Validation (Before the Tool Ever Sees the Call)
Every MCP tool exposes a JSON Schema for its input parameters. Validate incoming calls against that schema at the gateway before proxying. This is not optional — it's your first line of defense against prompt injection attacks that try to smuggle malicious parameters through LLM-generated tool calls.
// Go: validate MCP tool call params against registry schema
package gateway
import (
"github.com/xeipuuv/gojsonschema"
)
func validateToolCall(toolSlug string, params map[string]any) error {
schema := registry.GetSchema(toolSlug)
schemaLoader := gojsonschema.NewGoLoader(schema)
docLoader := gojsonschema.NewGoLoader(params)
result, err := gojsonschema.Validate(schemaLoader, docLoader)
if err != nil {
return fmt.Errorf("schema load error: %w", err)
}
if !result.Valid() {
msgs := make([]string, len(result.Errors()))
for i, e := range result.Errors() {
msgs[i] = e.String()
}
return fmt.Errorf("schema violation: %s", strings.Join(msgs, "; "))
}
return nil
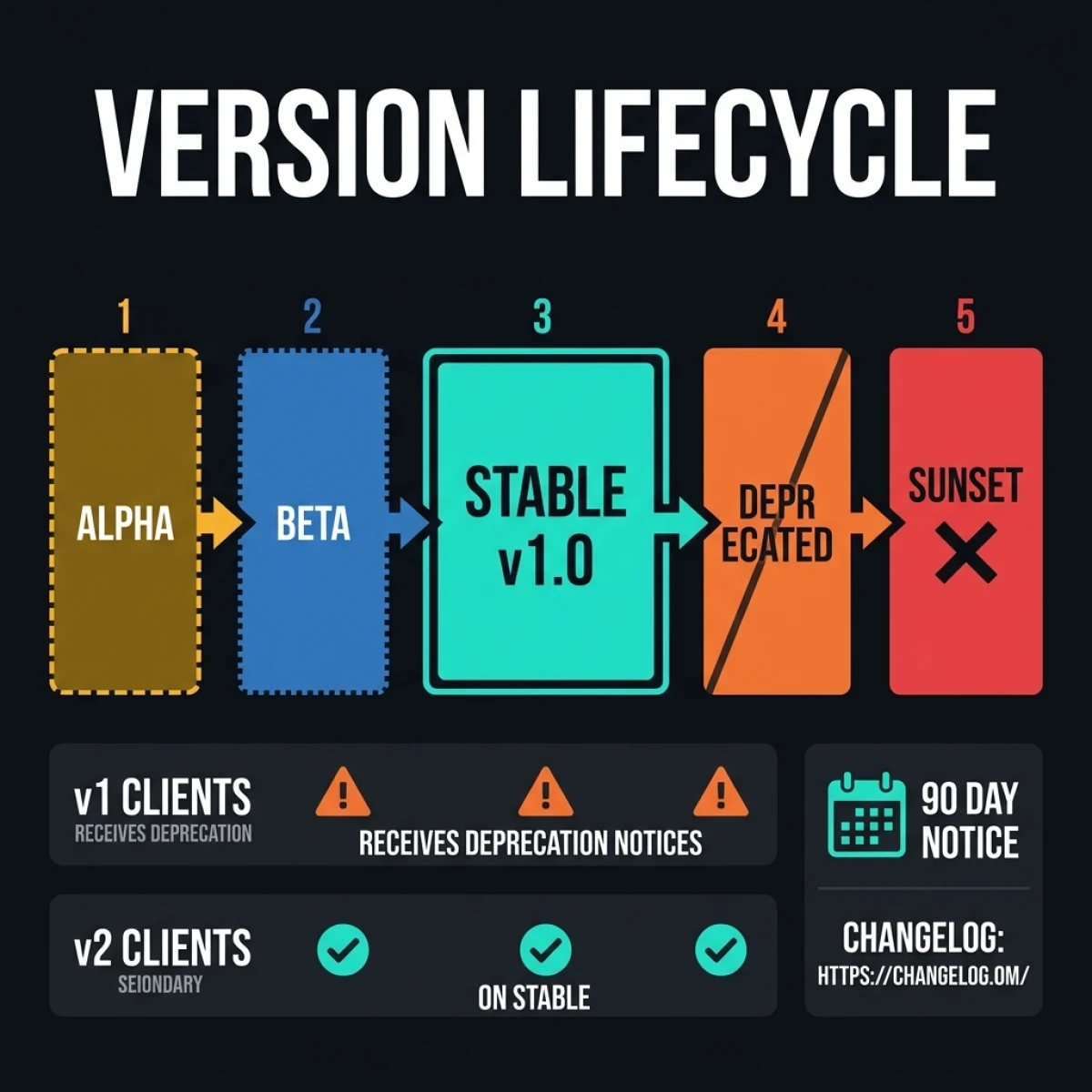
}Versioning and Deprecation
This is where most teams skip ahead and regret it. Tool servers change. Parameters get renamed. A new required field appears. Without a versioning contract, you break clients silently.
The pattern that works: URL-path versioning at the gateway, semantic versioning on server metadata.
# Client calls a specific tool version via gateway
POST /mcp/v1/tools/jira-issue-creator/rpc # stable v1
POST /mcp/v2/tools/jira-issue-creator/rpc # new v2 interfaceThe registry stores each tool server's version, supported API versions, and deprecation date. When a version crosses its deprecation date, the gateway starts returning X-MCP-Deprecated: true headers with every response, and logs a warning in the audit trail. When the sunset date arrives, calls to the old version receive a 410 Gone with a migration guide URL.
Clients that follow the X-MCP-Deprecated header and update their tool references before sunset have zero disruption. Clients that don't get a clear error with enough context to fix it. That's the contract.
Stateless MCP Spec: July 2026 Implications
The July 2026 final release of the Model Context Protocol specification brings two changes that matter operationally.
Change 1: Session state moves to the token. In the earlier draft spec, session context was maintained as server-side state keyed to a connection ID. The final spec makes sessions token-bound — the server can be stateless because session context travels with the JWT. This is a win for horizontal scaling: you can run ten gateway replicas behind a load balancer with no session affinity.
The catch: your tokens get slightly heavier. If you were previously putting session context in server-side storage and referencing it by session ID, you now embed that context in the token claims (or in a shared KV store like Redis that all gateway replicas can reach). Design your session payloads to stay under 4KB or you'll hit header size limits in some HTTP proxies.
Change 2: Tool capability negotiation moves to initialization. Clients are now required to declare their tool capability requirements during the initialize handshake, not lazily. For your gateway, this means you can reject incompatible clients at session start rather than mid-call. That's actually cleaner from a governance perspective — you know exactly what capabilities a client is requesting before any data flows.
// Rust: validate client capability declaration at MCP init
use serde::{Deserialize, Serialize};
#[derive(Deserialize)]
pub struct McpInitRequest {
pub client_info: ClientInfo,
pub capabilities: ClientCapabilities,
}
#[derive(Deserialize)]
pub struct ClientCapabilities {
pub tools: Option<ToolCapabilities>,
pub resources: Option<ResourceCapabilities>,
}
pub fn validate_init(req: &McpInitRequest, registry: &Registry) -> Result<SessionToken, GatewayError> {
// Check declared tool capabilities against what the client is actually authorized for
if let Some(tools) = &req.capabilities.tools {
let authorized = registry.get_authorized_tools(&req.client_info.id)?;
let requested: Vec<&str> = tools.supported.iter().map(|s| s.as_str()).collect();
for tool in &requested {
if !authorized.contains(tool) {
return Err(GatewayError::Unauthorized(format!(
"Tool '{}' not in client authorization list", tool
)));
}
}
}
Ok(session_token_for(&req.client_info))
}The stateless spec alignment also has an important implication for MCP vs GraphQL and REST comparisons: MCP is now significantly closer to REST in its session model, which reduces one of the main objections enterprises had to running it at scale.
Comparison: MCP Gateway vs REST BFF vs GraphQL Federation
| Criterion | MCP Gateway | REST Backend-for-Frontend | GraphQL Federation |
|---|---|---|---|
| Protocol | JSON-RPC 2.0 over HTTP/SSE (stateless per July 2026 spec) | REST over HTTP/1.1 or HTTP/2 | GraphQL over HTTP/WebSocket |
| Primary consumer | AI agents and LLM tool systems | Frontend apps and mobile clients | Frontend apps needing flexible queries |
| Schema enforcement | JSON Schema per tool, validated at gateway | OpenAPI spec, validated per endpoint | GraphQL SDL, enforced by type system |
| Auth model | OAuth 2.0 + mTLS + API keys (mixed) | OAuth 2.0 / API keys | OAuth 2.0 / API keys + directive-level auth |
| Versioning | URL-path versioning + deprecation headers | URL-path or header versioning | Schema evolution + field deprecation |
| Rate limiting | Per-identity (token subject / cert CN / tenant) | Per-IP or per-API-key | Per-query complexity + per-user |
| Observability | JSON-RPC call audit log (tool slug + params + identity) | HTTP access logs + APM spans | Query tracing + resolver-level metrics |
| Multi-tenancy | Namespace-scoped tool registry per tenant | Custom per-tenant routing logic | Schema stitching per tenant (complex) |
| Prompt injection surface | Higher — LLM generates tool call params | Low — human writes request | Medium — LLM can generate queries via NLP-to-GraphQL |
| Ecosystem maturity | Rapidly growing (spec RC → final July 2026) | Mature, battle-tested | Mature, complex at scale |
| Best for | AI-first tool platforms, agentic backends | API aggregation for UIs | Complex data graphs with multiple consumers |
The key insight from this comparison: MCP isn't replacing REST or GraphQL in your existing systems. It's a new layer for AI tool consumption, and it needs its own gateway the same way GraphQL needed its own federation layer. The temptation to route MCP calls through your existing REST BFF is real — don't. The auth models, schema semantics, and error surfaces are different enough to cause incidents.
Shadow MCP Detection and Enforcement
Shadow MCP servers are the fastest-growing governance problem I see in mid-2026 enterprise environments. The profile is consistent: a developer or data scientist runs an MCP server locally during exploration, it gets committed to a shared environment, nobody removes it, and suddenly there's a non-audited pathway for any LLM-powered tool to hit internal infrastructure.
Four detection vectors work in practice:
1. Network port scanning on developer subnets. MCP servers typically run on ports 3000, 3001, or 8080. A weekly scan of internal subnets for open SSE endpoints (look for Content-Type: text/event-stream responses to HTTP GET on common MCP paths) surfaces most unregistered servers within minutes.
2. DNS request analysis. If your DNS logging captures internal lookups, watch for requests to .local hostnames on MCP-typical ports from your AI service accounts. Unregistered tool servers often use hostnames that don't match your naming convention.
3. LLM session audit logs. If you're running a corporate LLM gateway (which you should be — see the sovereign architecture guide), log every tool call made through it. Cross-reference tool server endpoints against your registry. Any endpoint not in the registry is a shadow server.
4. Agent identity certificates. If you've implemented mTLS for agents, any tool server that accepts calls from agents without validating the client cert is, by definition, ungoverned. A monthly certificate compliance check on your internal CA's audit log surfaces these quickly.
Enforcement has two modes. Soft enforcement (recommended for first 90 days): flag shadow servers in a dashboard, notify their probable owner, and give them 30 days to either register or shut down. Hard enforcement: block all network traffic to non-registry tool endpoints from agent identity ranges at the firewall. This is disruptive but necessary after a reasonable grace period.

Monday Morning: Your 3-Step Quick-Start
You don't need to build the full control plane on day one. Here's what actually makes sense to do first.
Step 1: Inventory every MCP server you're running today.
This is the most important step and the one most teams skip. Spend one morning doing an actual audit:
# On Windows: scan for listening MCP-typical ports on dev machines
netstat -an | Where-Object { $_ -match ':(3000|3001|8080|8888) ' -and $_ -match 'LISTENING' }Log every result in a spreadsheet: server name, port, owner, connected tools, auth status (none/key/oauth). That spreadsheet becomes your registry seed data.
Step 2: Stand up a central gateway with auth.
Even a minimal Nginx + JWT validation layer in front of your tool servers is better than no gateway. If you want something more structured, open-source options like Traefik with custom middleware or a thin FastAPI gateway with the auth patterns above get you running in a day.
The minimum viable gateway does three things: validates tokens, logs every call to a structured log destination, and has a single IP/hostname that all AI clients point to instead of individual tool server addresses.
Step 3: Publish your internal tool catalog.
Create a simple internal wiki page (or a read-only REST API endpoint) that lists every approved MCP server with its gateway URL, supported tool names, current version, and owner contact. This becomes the source of truth for developers adding tools to their agents.
When a developer asks "can my agent use the Jira MCP server?", the answer should be: check the catalog, grab the gateway URL, configure your agent with a scoped token. Not: "ask around and hope someone knows where it's running."
2027–2030 Roadmap: Federated MCP Mesh
The current state is centralized: one registry, one gateway, one organization. That's the right starting point. Where this evolves over the next few years is genuinely interesting.
2026 (now): Single-org registry + gateway. One team owns the registry. All MCP traffic routes through one gateway cluster. Auth is per-client within the org.
2027: Multi-tenant mesh. Large enterprises with multiple business units need federated registries — the logistics division's tool servers shouldn't be in the same registry namespace as the finance division's. Each BU runs its own registry instance; a top-level mesh router handles cross-BU tool calls with cross-namespace token translation.
2028: Cross-org tool federation. The most ambitious use case: an enterprise and its tier-1 supplier share a subset of tool capabilities. The supplier's MCP registry exposes a subset of tools to the enterprise's gateway. This requires inter-org identity federation (OIDC federation or public-key cross-signing) and is technically tractable — it's essentially the same problem that B2B API monetization platforms solve today.
2029–2030: Protocol-level federation. The MCP spec itself will evolve to include native federation primitives — the equivalent of GraphQL federation's supergraph concept, but for tool networks. Think a global MCP registry DNS where tool capabilities are discoverable across organizations with explicit trust boundaries.
This isn't science fiction. WS-Federation and OpenID Connect federation solved the identity equivalent of this problem fifteen years ago. The tool equivalent will follow the same arc.

Key Takeaways
- MCP in production requires a registry. Individual tool servers without a catalog are ungovernable at enterprise scale.
- Three auth patterns, not one. OAuth 2.0 for interactive users, mTLS for autonomous agents, HMAC-signed API keys for multi-tenant SaaS — pick based on client type, not convenience.
- Schema validate before you forward. Gateway-level JSON Schema validation blocks prompt injection at the parameter level — the cheapest defense you can add.
- Version everything from day one. URL-path versioning + deprecation headers costs almost nothing to implement and prevents a category of breaking-change incidents.
- Shadow MCP servers are real and findable. Network scan + DNS analysis + session audit log cross-reference will surface them.
- The stateless MCP spec (July 2026) is a scaling unlock. Design your gateway for horizontal replication now; the session model supports it.
- The Monday checklist is enough to start. Inventory → gateway → catalog. Don't wait for a perfect architecture.
FAQ
Can I use an existing API gateway (Kong, AWS API Gateway) as my MCP gateway?
Yes — with caveats. General-purpose API gateways handle HTTP routing and rate limiting fine, but they don't understand MCP-specific semantics like tool schema validation, JSON-RPC error formats, or SSE connection management. You'll typically add a thin middleware layer or a custom plugin that handles MCP-specific logic while letting the outer gateway handle infrastructure concerns. Kong has a community MCP plugin as of mid-2026; AWS API Gateway requires a custom authorizer lambda.
Does the stateless MCP spec mean I can stop thinking about session management?
It simplifies session management — you don't need sticky sessions or shared session state between gateway replicas. But you still need to manage token TTLs, refresh flows, and revocation lists. "Stateless" refers to the server's transport state, not your auth lifecycle.
How do I handle MCP tool calls that need to act across multiple downstream services in a single call?
This is the composition problem, and MCP doesn't solve it at the protocol level by design. Your tool server implementation handles downstream orchestration. From the gateway's perspective, it's still one tool call with one set of params and one response. If you need transaction-like semantics across multiple services, implement a saga-style orchestration pattern inside the tool server, not at the gateway.
What's the right log retention for MCP audit logs?
Treat MCP audit logs like API access logs for sensitive internal services — minimum 90 days hot, 1 year cold. If your MCP tools can access PII or financial data, align with your longest applicable regulatory retention requirement (typically 7 years for financial records in most jurisdictions). Log the tool slug, calling identity, param hash (not raw params if they contain PII), response status, and latency at minimum.
Can we use MCP alongside our existing REST APIs, or does it replace them?
Alongside, not replace. REST APIs remain the right choice for UI-facing data access, third-party integrations, and any interface where a human is writing the request. MCP is purpose-built for LLM-generated tool calls where the AI is the client. Running both is normal and recommended — the MCP vs REST vs GraphQL comparison covers this in more detail.
How do I prevent an LLM from calling a tool it shouldn't have access to?
Two-layer enforcement. First, scope the token/cert at auth time to only the tools that identity is allowed to call — the gateway enforces this before the call ever reaches the tool server. Second, include the allowed tool list in the MCP initialize response so the LLM's tool-calling system only generates calls for tools in its visible capability set. Defense in depth: scoped tokens catch misconfigurations, capability filtering prevents the calls from being generated in the first place.
About the Author
Vatsal Shah is an AI architect and technical leader based in India, specializing in production LLM systems, enterprise AI governance, and agentic architectures. He has advised engineering teams across logistics, SaaS, and fintech sectors on deploying AI systems that are auditable, scalable, and secure. His work focuses on the gap between "AI in the demo" and "AI in production" — and specifically on the infrastructure, governance, and organizational patterns that bridge that gap.
Connect at shahvatsal.com or explore the full MCP production cluster for more enterprise implementation guides.
Conclusion
MCP is maturing fast — faster than most enterprise security and platform teams expected. The protocol is solid. The ecosystem is growing. And the governance layer is, right now, dangerously underdeveloped at most organizations running it in production.
The answer isn't to slow down MCP adoption. It's to build the registry, the gateway, and the audit trail now — before the first compliance review asks for them. The patterns in this article are battle-tested. The Monday morning checklist is deliberately achievable. Start there.
If you're working through an enterprise MCP architecture review and want a second opinion on your design, reach out — I'm happy to look at what you're building.


