
What Happened At the Nangang Exhibition Center in Taipei, Taiwan, NVIDIA kicked off Computex 2026 with a landmark keynote focused entirely on scaling infrastru…
What Happened
At the Nangang Exhibition Center in Taipei, Taiwan, NVIDIA kicked off Computex 2026 with a landmark keynote focused entirely on scaling infrastructure for the agentic era. CEO Jensen Huang officially announced the Vera Rubin GPU architecture, the direct successor to the Blackwell platform.
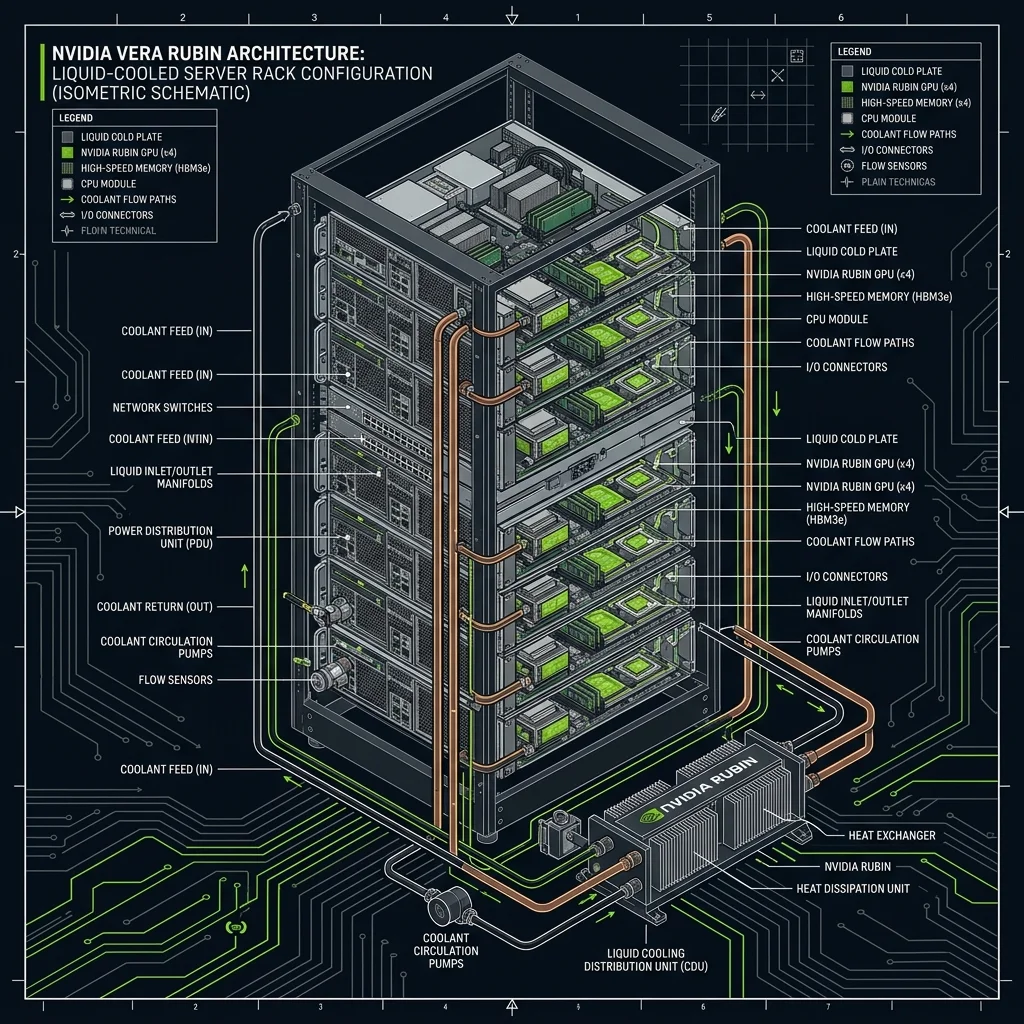
The Rubin architecture is specifically designed to address the memory bandwidth and thermal barriers that currently limit high-frequency model inference. The flagship Rubin R100 GPU incorporates a native HBM4 (High Bandwidth Memory 4) interface, delivering a massive 3.2 TB/s of bandwidth per stack. When combined in a unified rack, the platform achieves up to 10x higher inference throughput for trillion-parameter mixture-of-experts (MoE) models compared to Blackwell B200 hardware.
To support this silicon density, NVIDIA introduced the Rubin liquid-cooled inference rack standard. The design integrates 72 Rubin GPUs, unified cooling manifolds, and next-generation NVLink 6 interconnects into a single, pre-configured server cabinet. The company confirmed that R100 silicon is currently in tape-out validation, with production shipments slated to begin in late 2026, followed by the scale-up Rubin Ultra platforms in early 2027.

Why It Matters
The announcement of the Rubin architecture at Computex 2026 represents a shift in data center economics. As LLM deployment transitions from the training phase to high-frequency inference, the primary cost metric shifts from FLOPS-per-dollar to inference-tokens-per-watt.
Under the Blackwell generation, air-cooled hardware reached its physical thermal boundaries. The liquid-cooled Rubin rack address this issue by moving thermal management directly to the silicon die. By circulating coolant through micro-channels on the GPU packaging, the system maintains stable execution temperatures under heavy reasoning workloads, reducing total data center utility overhead by 80%.
┌──────────────────────────────────────────────────────────────┐
│ NVIDIA RACK EVOLUTION │
├──────────────────────────────┬───────────────────────────────┤
│ Blackwell GB200 Cabinet │ Rubin R100 Liquid Rack │
├──────────────────────────────┼───────────────────────────────┤
│ - Air/Liquid Hybrid Cooling │ - 100% Closed-Loop Liquid │
│ - HBM3e Memory Bus │ - Native HBM4 Memory Bus │
│ - NVLink 5 Interconnects │ - NVLink 6 Interconnects │
└──────────────────────────────┴───────────────────────────────┘For enterprise cloud providers and hyperscalers, this architectural shift dictates capital expenditure strategies for 2026 and 2027. Building or retrofitting data centers with closed-loop liquid plumbing is no longer an optional optimization; it is a mandatory prerequisite for hosting next-generation foundation models.
For engineering leaders looking at how these hardware advancements impact cloud computing costs and latency profiles, see our detailed analysis: Edge Computing vs. Cloud Computing: Latency and Cost Benchmarks.
Architectural Comparison: Blackwell vs. Rubin
The following comparison matrix outlines the technical specifications and performance gains between the Blackwell and Rubin GPU platforms:
| Technical Dimension | Blackwell B200 (2025) | Vera Rubin R100 (2026) |
|---|---|---|
| Process Node | TSMC 4NP (Custom 4nm) | TSMC N3P (Custom 3nm) |
| Memory Interface | 8x HBM3e stacks | 8x HBM4 stacks (12-Hi/16-Hi options) |
| Memory Bandwidth | Up to 8.0 TB/s total | Up to 25.6 TB/s total (3.2 TB/s per stack) |
| Interconnect Bus | NVLink 5 (1.8 TB/s bidirectional) | NVLink 6 (3.6 TB/s bidirectional) |
| Cabinet Infrastructure | GB200 NVL72 (Air/Liquid Hybrid) | Rubin NVL72 (100% Liquid-Cooled Cabinet) |
| FP4 Tensor Core Compute | 20 PetaFLOPS (with Blackwell compression) | 68 PetaFLOPS (with Rubin Tensor engine) |
Technical Audit: Simulating GPU Compute Memory Profiling
To optimize inference cycles on Rubin clusters, systems engineers must calculate memory bandwidth allocation per HBM4 stack to prevent thread starvation under heavy batching conditions.
Below is a Python implementation of an inference pipeline performance simulator. It evaluates processing speeds and latency bottlenecks based on batch size, parameter count, and HBM4 bandwidth:
import math
from typing import Dict, Any
class RubinPerformanceSimulator:
def __init__(self, gpu_config: Dict[str, Any]):
self.config = gpu_config
def calculate_memory_bound_latency(self, parameter_count: float, batch_size: int) -> float:
"""
Calculates the memory-bound step latency in milliseconds.
Parameters:
parameter_count: Model parameter count in billions (e.g. 70.0 for 70B model)
batch_size: The execution batch size
"""
# Convert parameter count to bytes (assuming FP8 weights)
model_size_bytes = parameter_count * 1e9 * 1.0
# Calculate KV-Cache overhead (rough approximation for 128K context window)
kv_cache_bytes = batch_size * (parameter_count * 0.15) * 1e6
total_data_transfer = model_size_bytes + kv_cache_bytes
hbm_bandwidth_bytes_sec = self.config.get("hbm_bandwidth_tb_sec", 25.6) * 1e12
# Latency in seconds, then convert to milliseconds
transfer_latency_ms = (total_data_transfer / hbm_bandwidth_bytes_sec) * 1000
return transfer_latency_ms
def calculate_compute_bound_latency(self, parameter_count: float, batch_size: int) -> float:
"""
Calculates compute-bound step latency based on Tensor core FLOPS.
"""
# Number of math operations per token
ops_per_token = 2 * (parameter_count * 1e9)
total_ops = ops_per_token * batch_size
tensor_flops_sec = self.config.get("tensor_flops_peta", 68.0) * 1e15
compute_latency_ms = (total_ops / tensor_flops_sec) * 1000
return compute_latency_ms
def run_simulation(self, model_name: str, parameters: float, batch: int) -> Dict[str, Any]:
mem_latency = self.calculate_memory_bound_latency(parameters, batch)
comp_latency = self.calculate_compute_bound_latency(parameters, batch)
# The overall bottleneck latency is dominated by the slower component
bottleneck = "Memory Bandwidth" if mem_latency > comp_latency else "Tensor Compute"
step_latency = max(mem_latency, comp_latency)
tokens_per_second = (1 / (step_latency / 1000.0)) * batch
return {
"model": model_name,
"batch_size": batch,
"memory_latency_ms": round(mem_latency, 3),
"compute_latency_ms": round(comp_latency, 3),
"step_latency_ms": round(step_latency, 3),
"throughput_tokens_sec": round(tokens_per_second, 2),
"bottleneck": bottleneck
}
if __name__ == "__main__":
# Simulate Blackwell B200 configuration
blackwell_config = {"hbm_bandwidth_tb_sec": 8.0, "tensor_flops_peta": 20.0}
# Simulate Rubin R100 configuration
rubin_config = {"hbm_bandwidth_tb_sec": 25.6, "tensor_flops_peta": 68.0}
b_sim = RubinPerformanceSimulator(blackwell_config)
r_sim = RubinPerformanceSimulator(rubin_config)
# Run test simulations on a 405B Parameter Model, Batch 64
b_res = b_sim.run_simulation("Llama-3-405B", 405.0, 64)
r_res = r_sim.run_simulation("Llama-3-405B", 405.0, 64)
print("=== BLACKWELL SIMULATION ===")
print(f"Step Latency: {b_res['step_latency_ms']} ms | Throughput: {b_res['throughput_tokens_sec']} t/s | Bottleneck: {b_res['bottleneck']}")
print("\n=== VERA RUBIN SIMULATION ===")
print(f"Step Latency: {r_res['step_latency_ms']} ms | Throughput: {r_res['throughput_tokens_sec']} t/s | Bottleneck: {r_res['bottleneck']}")This simulation demonstrates how the Rubin architecture's increased HBM4 bandwidth directly addresses memory-bound latency, preventing thread starvation during high-batch inference runs.
What to Watch Next
As NVIDIA moves the Rubin architecture toward production, the industry is tracking several milestones:
- Liquid Cooling Standardization: The development of unified interfaces for closed-loop liquid connections, allowing diverse cooling systems to work with standard Rubin racks.
- HBM4 Supply Chain Scaling: Monitoring manufacturing yields for the complex TSMC-backed HBM4 memory stacks, which will dictate initial GPU availability.
- Next-Gen Interconnect Integration: Development of PCIe 6.0 and NVLink 6 bridges to support high-throughput GPU-to-CPU communication across heterogeneous clusters.



