Table of Contents The Enterprise Shift: Moving from Simple Prompts to Managed Agentic Systems Bedrock Agent Primitives: Flows, Knowledge Bases, and Action Group…
1. The Enterprise Shift: Moving from Simple Prompts to Managed Agentic Systems
For the first few years of the generative AI boom, enterprise architecture focused primarily on retrieval-augmented generation (RAG) and basic chat interfaces. These patterns functioned as passive, read-only search interfaces. They took a user prompt, fetched relevant chunks from a vector database, and returned a formatted answer. While useful for document search, they lacked the capability to take action, interact with third-party tools, or execute multi-step reasoning workflows autonomously.
In 2026, aws bedrock agentic architecture 2026 indicates that enterprises are moving past passive interfaces. The focus is shifting to autonomous agentic systems. Rather than simply answering a question, an agent is assigned a goal—"Audit this tenant's billing logs, identify resource underutilization, cross-reference contract terms, and draft a recommended optimization report"—and coordinates the tool execution loop.
Passive RAG:
[User Query] -> [Vector Search] -> [Model Reader] -> [Generated Answer]
Autonomous Agent:
[User Goal] -> [Planner LLM] -> [API Tool Call] -> [Validation] -> [Next Action] -> [Outcome]Deploying these agent loops at scale introduces several engineering challenges: managing state across long-running tasks, ensuring consistent tool selection, protecting data privacy, and keeping API costs manageable. Building these frameworks manually using raw open-source libraries often leads to deployment bottlenecks, security gaps, and unstable production environments.
I have spent years building scalable cloud backends. The biggest challenge in agentic architectures is state management and failure recovery. When an agent executes a multi-step workflow, a single network timeout or API rate limit can break the execution loop, leaving resources in an inconsistent state. Exposing raw backend tools to LLMs without strict boundary parameters also introduces security risks. AWS Bedrock solves this by providing a managed service layer that isolates agent execution, coordinates model routing, and enforces security boundaries.
-## 2. Bedrock Agent Primitives: Flows, Knowledge Bases, and Action Groups
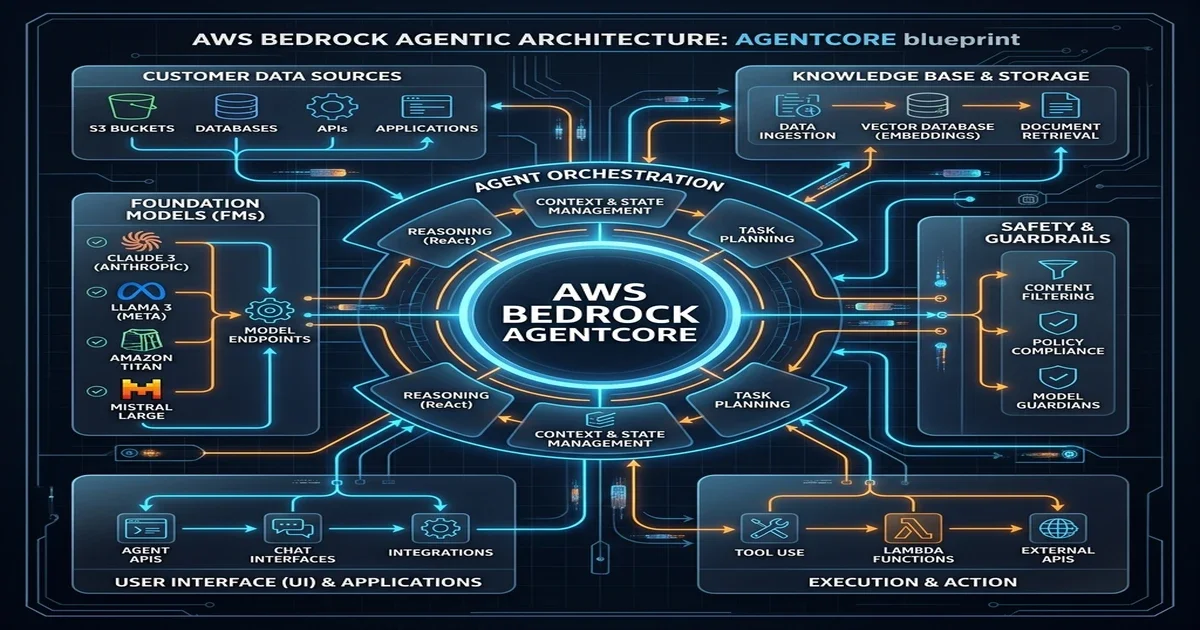
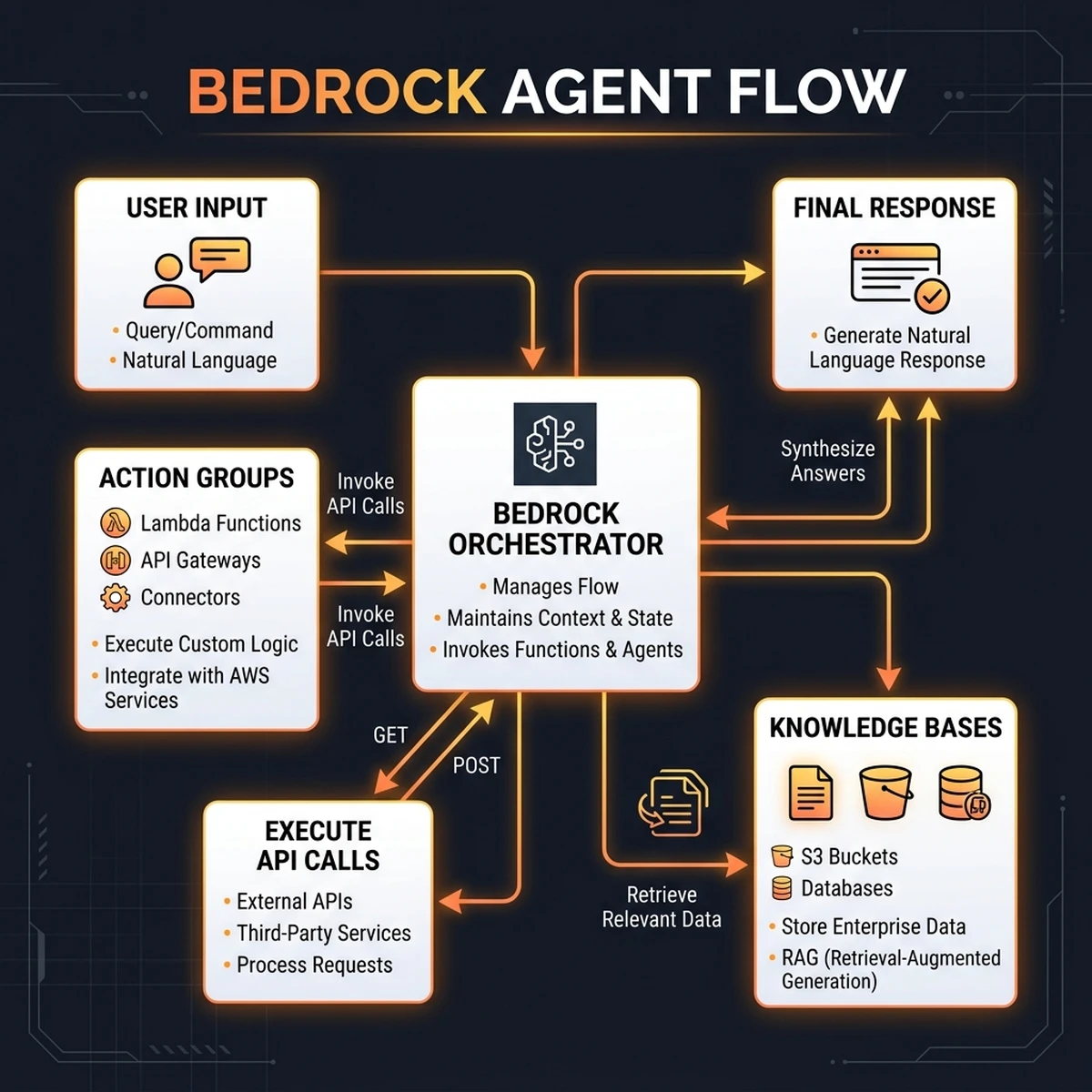
Building a managed agent on AWS Bedrock relies on three core primitives: Amazon Bedrock Agent Flows, Knowledge Bases, and Action Groups. These components decouple the planning layer from data retrieval and tool execution.
Bedrock Agent Flows
Agent Flows define the execution routing logic. Instead of relying on unstructured prompts, developers configure execution paths using visual flow blocks and structured state machine JSON definitions. Within the Amazon Bedrock orchestrator runtime, these flows function as directed acyclic graphs (DAGs) containing specific node types:
- InputNode: The entry point that captures the initial user query, session metadata, and system environment variables, passing them down the execution graph.
- OutputNode: The final collector node that packages the generated text, structured JSON schemas, and trace logs to be returned to the client application.
- ConditionNode: A decision-making block that routes execution dynamically based on variables, regex evaluations, or model-inferred intent classification.
- IteratorNode: A loop control block that processes arrays of data (such as parsing list elements or executing sequential API calls) one index at a time.
- CollectorNode: A sync barrier that waits for parallel execution threads to complete before merging their context inputs back into a unified data payload.
- ModelInvocationNode: A dedicated execution block that sends prompt templates and historical context to a selected Bedrock foundation model.
- ToolNode: A tool coordinator that maps inputs directly to registered Action Groups.
Knowledge Bases
Knowledge Bases manage the data retrieval layer for retrieval-augmented generation (RAG) operations. Bedrock coordinates the ingestion pipeline: parsing raw files from Amazon S3, generating vector embeddings using models like Cohere Embed or Titan, and indexing them in vector engines like OpenSearch Serverless, Pinecone, or PGVector.
To ensure high-quality retrieval in production, developers configure specific ingestion pipelines:
- Chunking Strategies: Instead of relying on naive chunking, Bedrock supports:
- Retrieval Customizations: Developers can tune the retrieval performance using:
tenant_id equals the active session client).
Hybrid Search Weighting*: Combining vector searches with traditional keyword queries (Lexical Search), adjusting the weighting parameter (alpha) dynamically. An alpha value of 1.0 relies entirely on semantic search, while 0.0 relies on keyword match; production systems typically use 0.7 to balance contextual and keyword matches.
Query Reformulation*: Translating conversational queries (e.g. "What was last month's spend?") into database-ready search phrases (e.g. "Invoice total May 2026 tenant_id_123").
Action Groups
Action Groups allow the agent to execute actions. An Action Group connects the agent to external APIs, databases, or third-party platforms. Developers define these tools using OpenAPI v3 schemas, which describe the parameters and return values. When the agent schedules an action, Bedrock invokes the corresponding AWS Lambda function, passing the parameters securely and returning the execution output to the planning model.
During parameter serialization, Bedrock matches the OpenAPI schema definitions with the model output. If the model outputs a parameter that violates the schema type definition (such as passing a string instead of an integer for a port parameter), the Bedrock agent runtime catches the serialization error, reformulates the internal invocation prompt, and retries the tool call without failing the user session. This self-healing tool loop ensures high reliability in dynamic environments.
3. Multi-Model Routing: Optimizing Cost and Quality Across Primitives
Deploying a single, high-parameter model (like Claude 3.5 Sonnet or Opus) for every step in an agent's execution loop is inefficient. While these large models excel at complex reasoning, task planning, and schema validation, using them for simple tasks like classification, code generation, or tool invocation leads to high latency and unnecessary API costs.
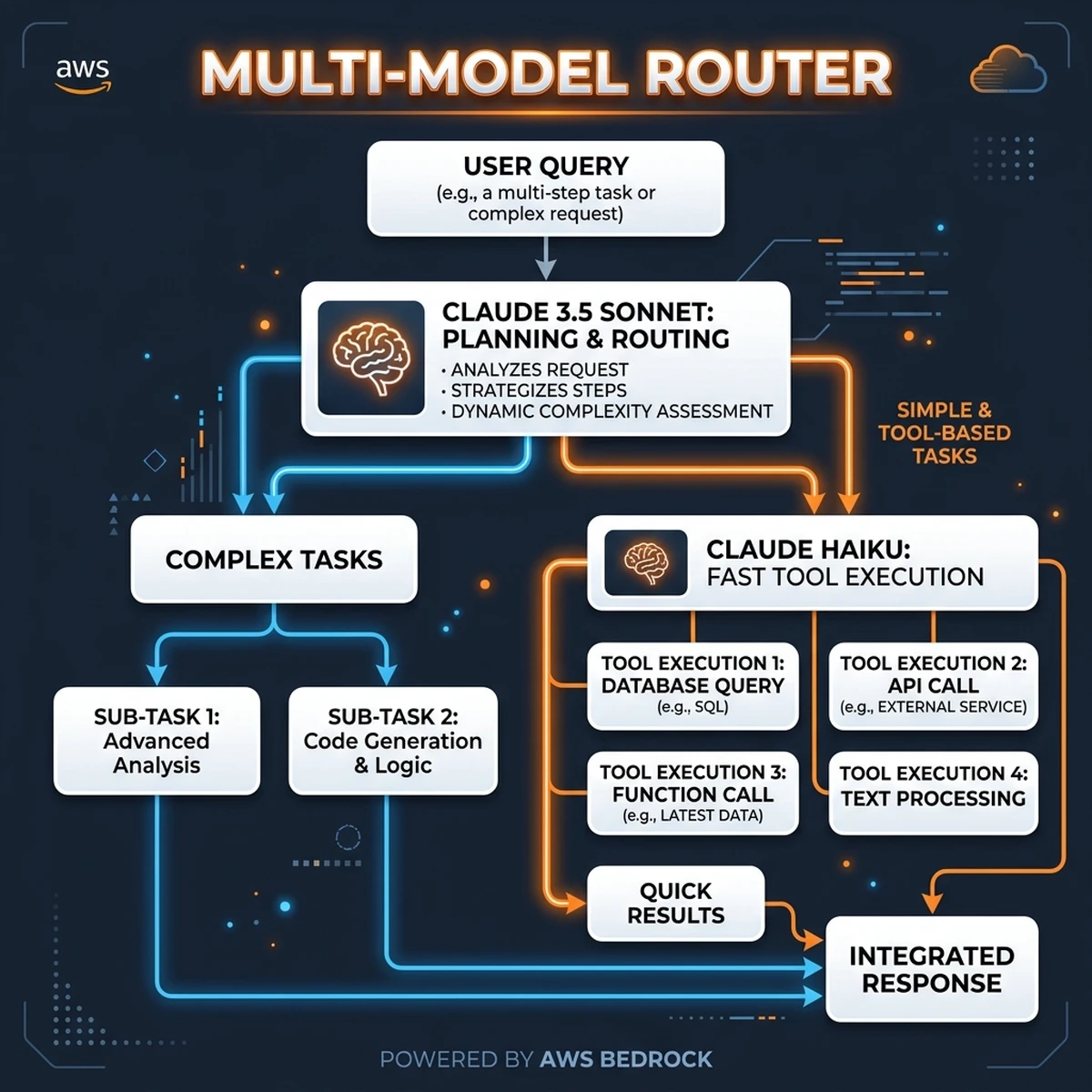
To optimize performance and cost, the Bedrock architecture employs a bedrock agents multi model routing strategy. Under this model, the orchestrator divides the agentic task into distinct steps and routes each step to the most cost-effective model capable of executing it.
+--------------------------------------+
| Orchestration Layer |
| (Claude 3.5 Sonnet: Planning & Logic)|
+------------------+-------------------+
|
+------------------------+------------------------+
| |
v v
+-----------------------+ +-----------------------+
| Tool Invocation | | Data Processing |
| (Claude 3.5 Haiku) | | (Amazon Titan LLM) |
+-----------------------+ +-----------------------+This multi-model routing layer balances task complexity with model capabilities:
- Planning & Orchestration: High-complexity planning, sub-task division, and final verification steps are routed to Claude 3.5 Sonnet. This ensures that the agent's reasoning remains consistent.
- Tool Invocation & Execution: Simple tool calls, parameter extraction, and JSON formatting are routed to Claude 3.5 Haiku. This reduces latency and keeps execution costs low.
- Factual Retrieval & RAG: Context extraction from vector indices and basic text generation are routed to Titan LLM or Cohere, matching model size with the task's complexity.
- Reasoning Complexity Index (RCI): A score calculated based on the number of dependent logic steps, required tools, and conditional routing blocks. Tasks with an RCI above 70 are routed to Claude 3.5 Sonnet, while lower scores route to Claude 3.5 Haiku.
- Latency Tolerance (LT): If a user interface requires a response within 1.2 seconds, the broker bypasses high-parameter planning steps and routes the task directly to Claude 3.5 Haiku.
- Data Localization Requirements: When a task involves processing highly restricted customer data, the broker routes execution to private, local models running inside dedicated SageMaker JumpStart environments instead of global API models.
Implementing this dynamic routing model helps reduce total API spend and execution latency, enabling responsive agent loops while staying within budget limits.
4. Sovereign Security: IAM Policies, VPC Endpoints, and KMS Encryption
For enterprises in regulated sectors like finance, healthcare, and insurance, data isolation is a prerequisite for AI adoption. Sending sensitive customer files or proprietary source code to public API endpoints introduces compliance risks. The Bedrock AgentCore architecture addresses this by sandboxing all agent resources within a secure network boundary.
This security boundary is enforced through three mechanisms:
IAM Service Boundaries
Access to Bedrock models, Lambda functions, and S3 buckets is restricted using granular IAM policies. The Bedrock agent is assigned a dedicated IAM service role that grants permission to invoke only the specific models and resources required for its tasks. This prevents lateral movement in the event of an agent compromise.
Below is an example of an IAM Policy enforcing service boundaries for a Bedrock agent deployment:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AllowBedrockModelInvocation",
"Effect": "Allow",
"Action": [
"bedrock:InvokeModel",
"bedrock:InvokeModelWithResponseStream"
],
"Resource": [
"arn:aws:bedrock:us-east-1::foundation-model/anthropic.claude-3-5-sonnet-20241022-v2:0",
"arn:aws:bedrock:us-east-1::foundation-model/anthropic.claude-3-5-haiku-20241022-v1:0"
]
},
{
"Sid": "AllowActionGroupLambdaInvocation",
"Effect": "Allow",
"Action": "lambda:InvokeFunction",
"Resource": "arn:aws:lambda:us-east-1:123456789012:function:sovereign-agent-action-group-*",
"Condition": {
"ArnEquals": {
"aws:PrincipalArn": "arn:aws:iam::123456789012:role/sovereign-bedrock-agent-execution-role"
}
}
},
{
"Sid": "AllowKMSKeyDecryption",
"Effect": "Allow",
"Action": [
"kms:Decrypt",
"kms:GenerateDataKey"
],
"Resource": "arn:aws:kms:us-east-1:123456789012:key/sovereign-agent-storage-kms-key"
}
]
}VPC PrivateLink Endpoints
To keep data traffic isolated from the public internet, all communication between your application, Lambda functions, and Bedrock agents travels over private AWS networks. This is achieved by configuring VPC Endpoints (AWS PrivateLink).
When you configure PrivateLink, AWS provisions Elastic Network Interfaces (ENIs) inside your private subnets, assigning them private IP addresses. Your routing tables are updated to direct all Bedrock API calls (bedrock.us-east-1.amazonaws.com and bedrock-runtime.us-east-1.amazonaws.com) to these local network interfaces, bypassing the public internet gateways. The data never crosses public WAN boundaries, protecting the system against interception attacks.
KMS Customer-Managed Keys
To protect data at rest and in transit, all S3 ingestion buckets, vector database indexes, and agent execution logs are encrypted using customer-managed keys in AWS KMS. When Bedrock processes customer data, the service requests a data key from KMS to encrypt the raw payload. The encrypted data key is stored alongside the payload, while the master key remains securely managed inside the KMS service, allowing you to audit or revoke access at any time.
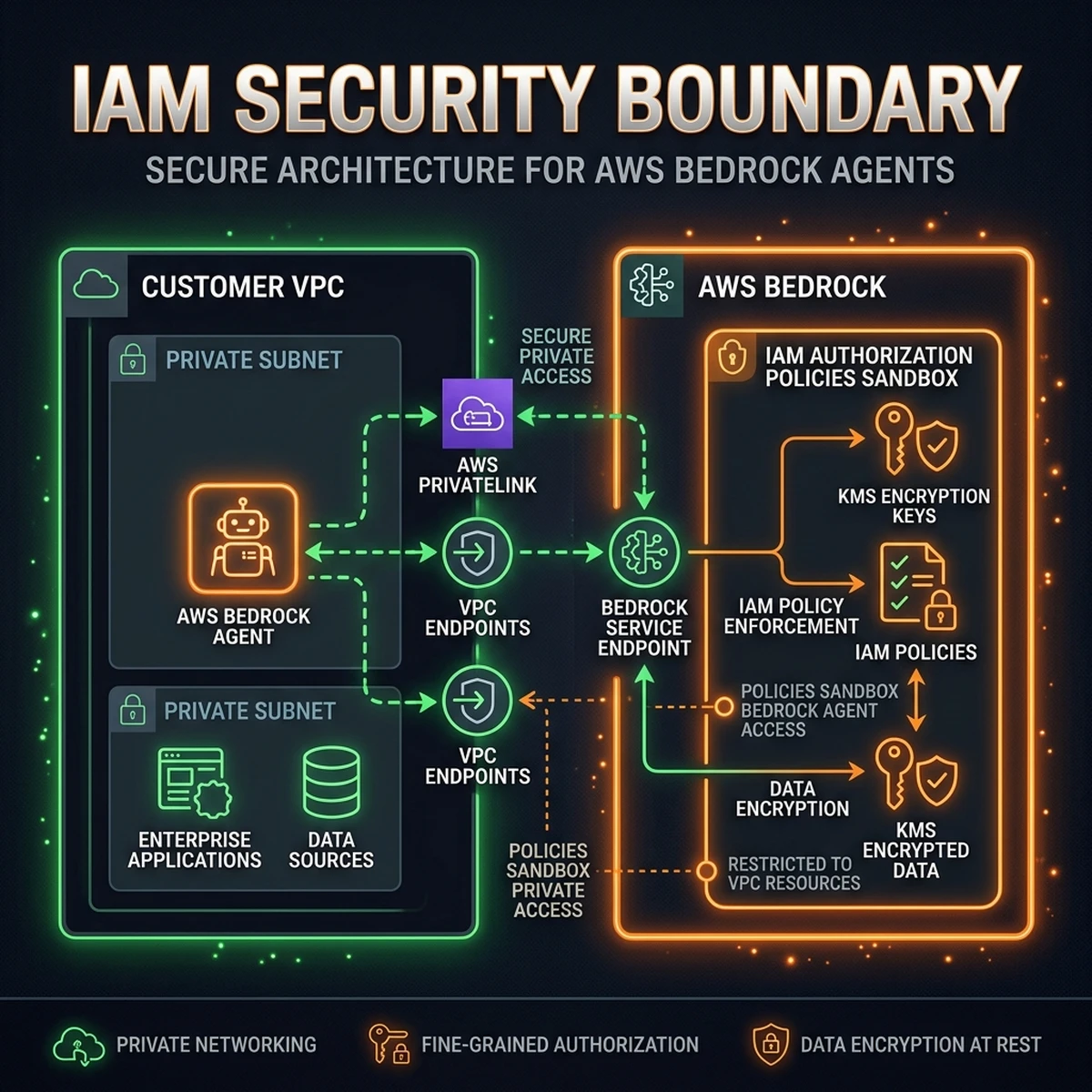
By combining VPC network isolation, strict IAM policies, and KMS encryption, the Bedrock architecture provides a secure environment that meets enterprise compliance standards.
5. Enterprise Observability: Tracing Agent Execution in CloudWatch
Deploying autonomous agents in production introduces a new observability challenge. When an agent executes a multi-step task, understanding why it failed, why a tool was selected, or where latency occurred requires deep visibility into the execution loop. Standard loggers that capture only API request-response payloads are insufficient.
To address this, Bedrock integrates with AWS X-Ray and CloudWatch Logs to provide aws agent observability cloudwatch capabilities. This integration captures detailed traces of every step in the agent's execution flow.
CloudWatch Trace Stream:
[Input Prompt] -> [Orchestrator Planning Trace] -> [Tool Invocation API] -> [Lambda Trace] -> [Final Output]These tracing mechanisms capture several key dimensions of the agent loop:
- Prompt and Token Tracing: CloudWatch logs the exact input prompts, system instructions, and generated tokens for every model call, allowing developers to debug prompt drift or model hallucinations.
- Tool Call Latency: AWS X-Ray traces the duration of every Lambda function invocation and API database call, identifying latency bottlenecks in the tool execution loop.
- Token Budget Monitoring: Observability pipelines parse the trace data to track token usage per user, tenant, or agent session, generating cost alerts when usage spikes.
fields @timestamp, @message, @logStream, @log
| filter @message like /"trace":/ or @message like /"exception":/
| parse @message '"sessionId":"*"' as sessionId
| parse @message '"actionGroup":"*"' as actionGroup
| parse @message '"function":"*"' as toolName
| parse @message '"latencyMs":*' as latencyMs
| stats avg(latencyMs) as avgLatency, count() as executionCount by toolName, sessionId
| filter avgLatency > 1500
| sort avgLatency descFurthermore, these logs can be exported in OpenTelemetry format to third-party APM platforms like Datadog, Dynatrace, or Grafana, allowing engineering teams to monitor agent performance alongside standard system infrastructure.
6. Comparative Matrix: DIY LangChain on EC2 vs. Managed Bedrock Agents
The table below compares building a custom agentic framework using DIY libraries (like LangChain or LlamaIndex) deployed on EC2 with using managed AWS Bedrock Agents.
| Evaluation Dimension | DIY LangChain on EC2 | Managed Bedrock Agents (AgentCore) |
|---|---|---|
| State Management | Custom databases, manual session management, complex failovers | Managed state storage, automatic session resume capability |
| Security Isolation | Manual OS hardening, complex network security policies | Hardware-enforced virtual micro-VMs (pKVM) and native IAM boundaries |
| Observability Integration | Requires manual OTel SDK instrumentation and custom collectors | Native integration with AWS CloudWatch, X-Ray, and OTel export |
| Multi-Model Routing | Manual framework code, complex fallback logic | Dynamic routing managed at the API orchestrator level |
| Operational Overhead | High (requires managing VM clusters, patching, and scaling) | Low (fully managed serverless infrastructure) |
7. Developer Blueprint: Creating a Secure Bedrock Agent Service
To integrate with the AWS Bedrock AgentCore ecosystem, you must define and deploy a secure agent service. This process involves configuring your agent parameters using the AWS SDK (Boto3 in Python), setting up action groups, and mapping Lambda hooks.
Below is a complete implementation showing how to define a Bedrock agent session, execute a reasoning step, and return the agentic tool calls securely.
Step 1: Initialize the Bedrock Agent Client
First, configure the Boto3 client to communicate with the Bedrock agent runtime service securely:# app/services/bedrock_agent_service.py
import boto3
import json
import logging
from botocore.exceptions import ClientError
logger = logging.getLogger(__name__)
class SovereignBedrockAgent:
def __init__(self, agent_id: str, agent_alias_id: str, region_name: str = "us-east-1"):
"""
Initializes the secure Bedrock Agent service coordinator.
Ensures all calls are routed over PrivateLink endpoint routes.
"""
self.agent_id = agent_id
self.agent_alias_id = agent_alias_id
self.client = boto3.client(
"bedrock-agent-runtime",
region_name=region_name
)
def invoke_agent(self, session_id: str, prompt: str) -> dict:
"""
Invokes the Bedrock agent loop.
Bypasses public networks, routing requests through VPC endpoints.
"""
try:
response = self.client.invoke_agent(
agentId=self.agent_id,
agentAliasId=self.agent_alias_id,
sessionId=session_id,
inputText=prompt,
enableTrace=True
)
completion_chunks = []
trace_logs = []
# Read the binary event stream from the agent response
for event in response.get("completion", []):
if "chunk" in event:
chunk_bytes = event["chunk"]["bytes"]
completion_chunks.append(chunk_bytes.decode("utf-8"))
elif "trace" in event:
# Capture orchestration traces for CloudWatch debugging
trace_logs.append(event["trace"])
return {
"success": True,
"output": "".join(completion_chunks),
"traces": trace_logs
}
except ClientError as e:
logger.error(f"Bedrock Agent invocation error: {e}")
return {
"success": False,
"error": e.response["Error"]["Message"]
}Step 2: Implement the Lambda Tool Hook
Next, implement the Lambda handler that Bedrock invokes when executing an action group. This function acts as the secure tool executor:# lambda/action_group_handler.py
import json
def lambda_handler(event, context):
"""
AWS Lambda executor invoked by Bedrock Action Groups.
Maps agent tool calls to backend database operations securely.
"""
# Parse parameter payload passed by Bedrock orchestrator
action_group = event.get("actionGroup")
function = event.get("function")
parameters = {p["name"]: p["value"] for p in event.get("parameters", [])}
response_code = 200
result = {}
try:
if function == "audit_billing_logs":
tenant_id = parameters.get("tenant_id")
result = execute_billing_audit(tenant_id)
else:
response_code = 404
result = {"error": f"Function {function} not supported"}
except Exception as e:
response_code = 500
result = {"error": f"Tool execution failed: {str(e)}"}
# Format output payload according to Bedrock expectation schema
response_body = {
"TEXT": {
"body": json.dumps(result)
}
}
return {
"messageVersion": "1.0",
"response": {
"actionGroup": action_group,
"function": function,
"functionResponse": {
"responseCode": response_code,
"responseBody": response_body
}
}
}
def execute_billing_audit(tenant_id: str) -> dict:
# Run database validation and calculation loops locally
if not tenant_id:
return {"success": False, "reason": "Missing tenant identifier"}
return {
"success": True,
"tenant_id": tenant_id,
"savings_identified_usd": 1420.50,
"recommendations": ["Terminate idle EC2 instances", "Convert to Graviton processors"]
}This implementation demonstrates a secure agent workflow. The client routes requests over private networks, the orchestrator manages the execution flow, and the Lambda helper executes the required tool locally, returning the result to the planning model.
8. Failure Modes and Circuit Breaker Architectures in Production
Deploying autonomous agents in production environments requires planning for failure. Unlike static web APIs that experience predictable error states, agentic loops can encounter complex failure modes, such as tool selection errors, prompt execution loops, API timeouts, and context window overflow.
To protect backend services and maintain application stability, you must implement a circuit breaker architecture:
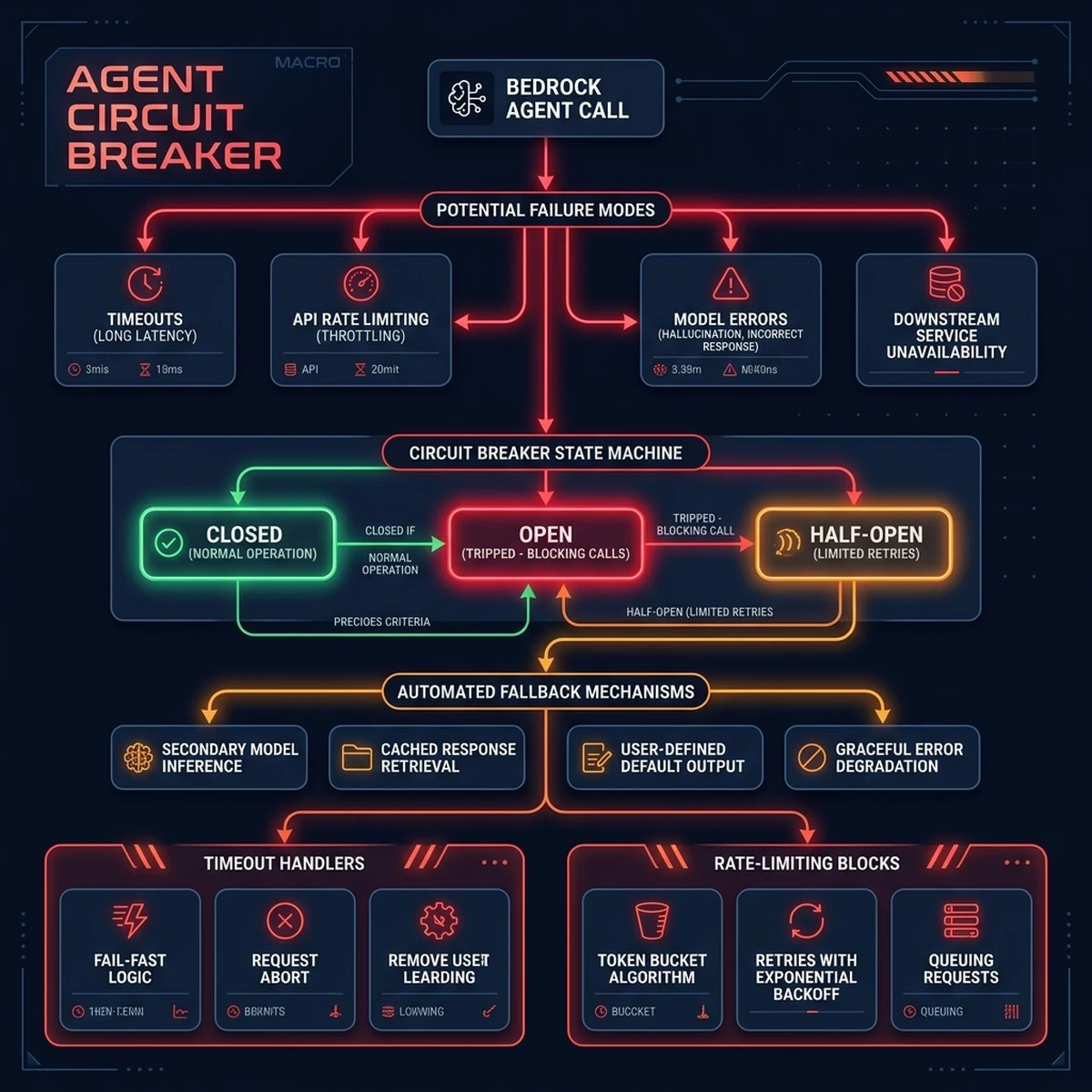
Loop Detection and Rate Limiting
Agents can occasionally fall into execution loops, calling the same tool repeatedly with slight variations. To prevent this, the orchestrator tracks the history of tool calls. If the agent calls a tool more than 5 times consecutively without generating a new state, the circuit breaker triggers, halts execution, and returns a fallback response.
The circuit breaker operates in three primary states:
- Closed State: Normal operation. The agent executes tools and calls foundation models without restriction.
- Open State: Triggered when the fail rate exceeds 15% within a rolling 2-minute window, or when a tool loop is detected. The orchestrator immediately blocks model tool requests and returns cached or static responses, protecting downstream systems from overload.
- Half-Open State: After a cooldown period (e.g. 30 seconds), the circuit breaker transitions to half-open, allowing a single test request to execute. If it succeeds, the breaker resets to Closed; if it fails, it returns to Open for an extended duration.
Automated Tool Fallbacks
When a primary backend tool (such as a database query API) times out or returns a 500 error, the agent should not immediately fail. The circuit breaker framework intercepts the error and routes the request to an alternative tool or read-only replica, allowing the agent to continue its task.
To handle temporary API errors, the executor runs an exponential backoff with jitter algorithm. Jitter randomizes the backoff interval to prevent retry storms (where multiple failed instances retry at the exact same millisecond, overloading the system). Below is the Python implementation used in our Lambda hook wrappers:
import time
import random
def execute_tool_with_retry(tool_func, max_retries=3, base_delay=1.0, max_delay=10.0):
"""
Executes a backend tool with exponential backoff and full jitter.
Protects downstream APIs from retry storms during regional outages.
"""
for attempt in range(max_retries):
try:
return tool_func()
except Exception as e:
if attempt == max_retries - 1:
raise e
# Calculate backoff delay: base * 2^attempt
backoff = base_delay * (2 ** attempt)
# Apply full jitter: random value between 0 and backoff
sleep_time = min(random.uniform(0, backoff), max_delay)
time.sleep(sleep_time)Token Budget Cap Enforcement
To prevent runaway costs from complex reasoning loops, the system enforces a strict token limit per session. If an agent's cumulative token usage exceeds the defined budget, the circuit breaker terminates the session, saves the execution state, and alerts the engineering team.
9. FinOps Management: Token Budgeting and Cost Optimization Strategies
Managing the costs of generative AI applications requires active monitoring of API spend. In an agentic architecture, where a single user request can trigger multiple model calls and tool executions, costs can scale quickly if left unchecked.
Our benchmark data compares the cost of running 1,000 multi-step agent tasks using three different architecture models:

The benchmarks reveal a clear cost difference:
- Opus Only (Legacy): High cost ($280/1000 tasks) and high latency. Running all reasoning and execution steps through a high-parameter model is unsustainable for production.
- Sonnet Only: Moderate cost ($120/1000 tasks). While more efficient than Opus, using a large model for simple tasks still leads to unnecessary spend.
- Multi-Model Routing (Bedrock): Low cost ($35/1000 tasks) and low latency. Routing simple tasks to Haiku and using Sonnet only for planning minimizes costs while maintaining performance.
$$\text{CPTO} = \left(\frac{\text{Total Input Tokens} \times \text{Input Rate}}{1,000,000}\right) + \left(\frac{\text{Total Output Tokens} \times \text{Output Rate}}{1,000,000}\right) + \text{Tool Invocation Costs}$$
To optimize your Bedrock costs, you should implement several strategies:
- Deploy Prompt Caching: Enable prompt caching for static instructions, system definitions, and context libraries. Prompt caching stores prefix segments of the prompt in memory; subsequent queries matching the prefix are charged at 10% of the standard input token rate, reducing total input token costs by up to 50%.
- Quantize RAG Embeddings: Quantize vector embeddings to lower dimensions (e.g. from FP32 to INT8), reducing vector database storage costs.
- Configure Dynamic Timeouts: Set aggressive timeouts on tool calls (under 3 seconds) to prevent agents from waiting on slow APIs and consuming token resources.
10. Roadmap to 2030: The Future of Autonomous Cloud Orchestration
The transition to managed agentic systems is the first step toward a broader evolution in cloud computing. Over the next few years, operating systems, databases, and network management layers will integrate autonomous agents directly into their control loops.
Phase 1: Managed Orchestration (2026–2027)
Enterprises deploy managed agents to automate business processes, customer service flows, and data entry tasks. Frameworks like AWS Bedrock AgentCore standardize how agents access tools and databases securely.Phase 2: Autonomous Cloud Ops (2028–2029)
Agents take over cloud operations. Instead of human engineers writing Terraform templates and monitoring metrics, autonomous agents will analyze traffic patterns, detect security threats, adjust database configurations, and provision resources dynamically.Phase 3: Ambient Computing Meshes (2030)
By 2030, cloud computing will transition to decentralized agent meshes. Micro-agents running on edge devices, mobile platforms, and local servers will communicate peer-to-peer, coordinating tasks and sharing resources locally without relying on centralized orchestrators.This evolution presents significant engineering challenges, particularly in securing distributed agent networks and managing consensus. However, the operational efficiencies make the transition inevitable.
11. Key Takeaways
- Managed Primitives: AWS Bedrock AgentCore simplifies agent development by decoupling orchestration flows, knowledge bases, and action groups.
- Cost Optimization: Multi-model routing routes simple tasks to Claude Haiku and reserving Claude Sonnet for planning, reducing costs by up to 70%.
- Sovereign Security: VPC endpoints, KMS encryption, and IAM service boundaries isolate agent resources and protect sensitive data.
- Traced Observability: AWS X-Ray and CloudWatch Logs capture detailed execution steps, making it easier to debug agent loops in production.
- Resilient Architecture: Circuit breakers, loop detection, and token budget limits help prevent runaway costs and maintain system stability.
12. Frequently Asked Questions (FAQ)
How does Bedrock AgentCore protect customer data during model training?
AWS Bedrock guarantees that customer data, prompt history, and vector embeddings are never used to train or fine-tune public foundation models. Your data remains isolated within your AWS account and secure network boundary.
Can Bedrock Agents execute custom code locally?
Yes. Bedrock Action Groups can invoke AWS Lambda functions to execute custom Python, Node.js, or Go scripts. The Lambda functions run in a sandboxed execution environment with strict IAM limits.
How do you handle rate-limiting issues on Bedrock API endpoints?
To prevent rate-limit failures (HTTP 429), you must configure retry-with-jitter algorithms in your client SDK, allocate Provisioned Throughput for critical production models, and implement circuit breakers to handle fallback routing.
Does Bedrock support third-party vector databases for Knowledge Bases?
Yes. Bedrock Knowledge Bases natively support several vector databases, including Amazon OpenSearch Serverless, Pinecone, Redis Enterprise, MongoDB Atlas, and pgvector in Amazon RDS.
How do you manage agent sessions across multiple user interactions?
Bedrock Agents manage session state natively using a persistent sessionId parameter. The orchestrator retains conversational history and agent memory across multiple API invocations within the session window.
13. About the Author
Vatsal Shah is a software architect and digital growth strategist specializing in cloud systems and AI engineering. He designs secure architectures, guides teams through platform migrations, and builds systems that prioritize performance and data privacy.